

Hillary Clinton and Donald Trump seem to be the nominees for the upcoming US presidential election in November 2016. The US presidential election in five months provokes already harsh attacks between the nominees – the election campaigns of Trump und Clinton evolve to one of the toughest competitions in the recent history of US presidential elections – primary via their social media channels.
To derive a more detailed understanding of the nominees’ appearance and fan base in social media channels, we analyzed the Facebook traffic of Clinton (approximately 3.6m Facebook fans) and Trump (approximately 8m Facebook fans) for over 12 months. Facebook is the leading social media websites in the US in 2016 (Experian, 2016) and may provide relevant and representative information about the nominees’ supporters and fans.
Analyzing the US elections with the CTSA index:
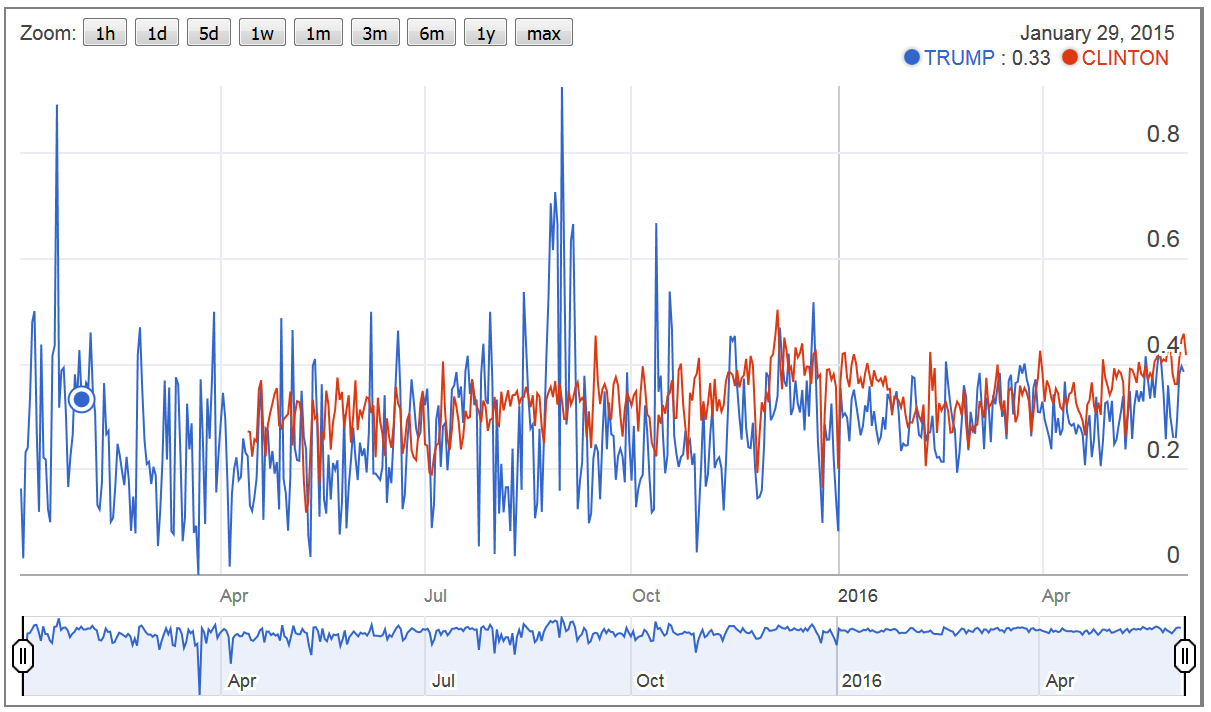
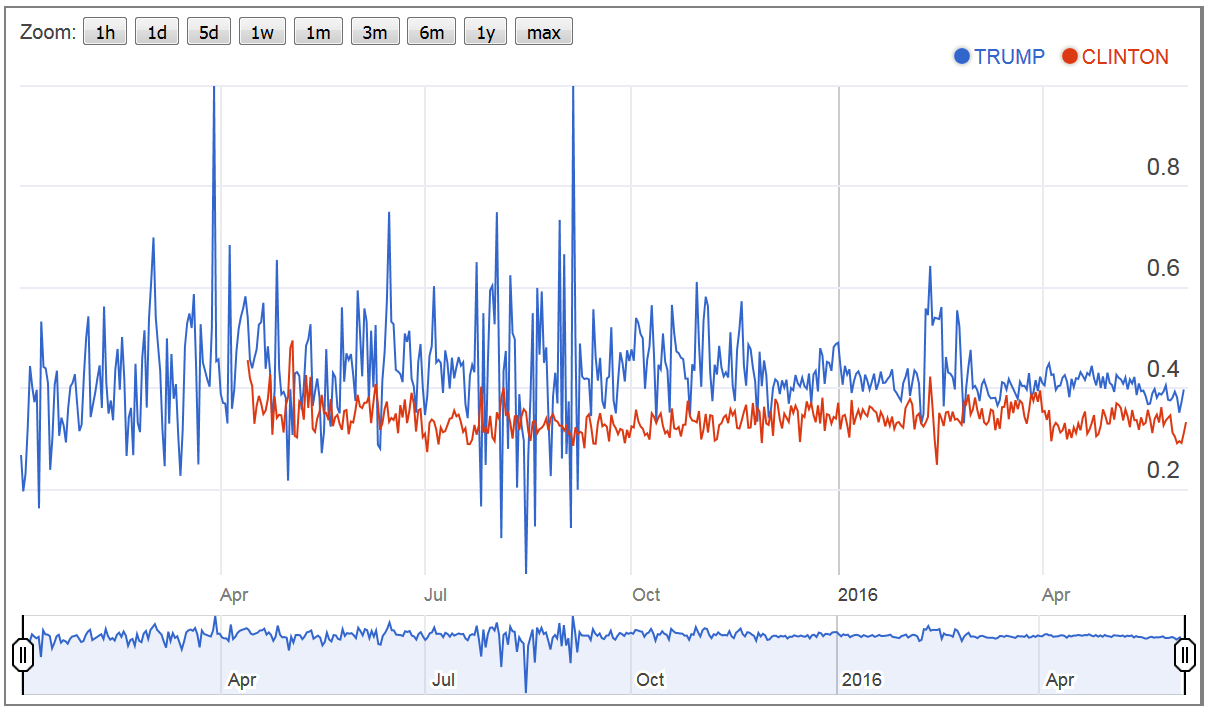
- The first figure shows the emotional atmosphere within the nominees’ communities. Specifically, negative expressed emotions (relative to positive expressed emotions) varies considerably among Clinton and Trump. Whereas Trump’s community tends to be more positive engaged (positive comments: 69.46%; negative comments: 30.46%), Clinton’s community is relative more negative engaged (positive comments: 65.94%; negative comments: 33.94%). However, the dispersion of emotions (controversy of comments), as shown in Figure 2, is much more notable in Trump’s community (coefficient of variation, as percent: Trump: 122.23 / Clinton: 115.31).
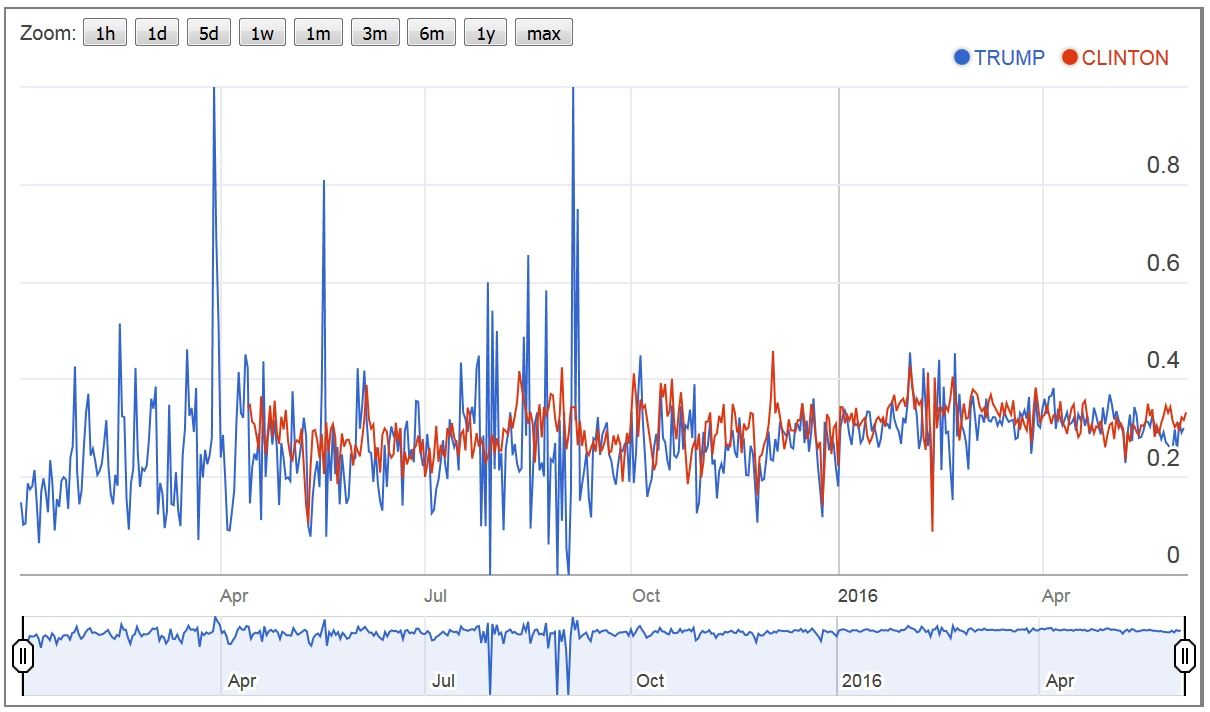
- The third figure shows how optimistic the followers express themselves. The data show that Clinton’s fan base is slightly more optimistic (31.13%), than Trump’s fans base (29.57%), whereby the trend shows, that there is a more positive development in Trump’s community. Again, the dispersion of optimistic comments is much more notable in Trump’s community (coefficient of variation, as percent: Trump: 130.12 / Clinton: 126.11).
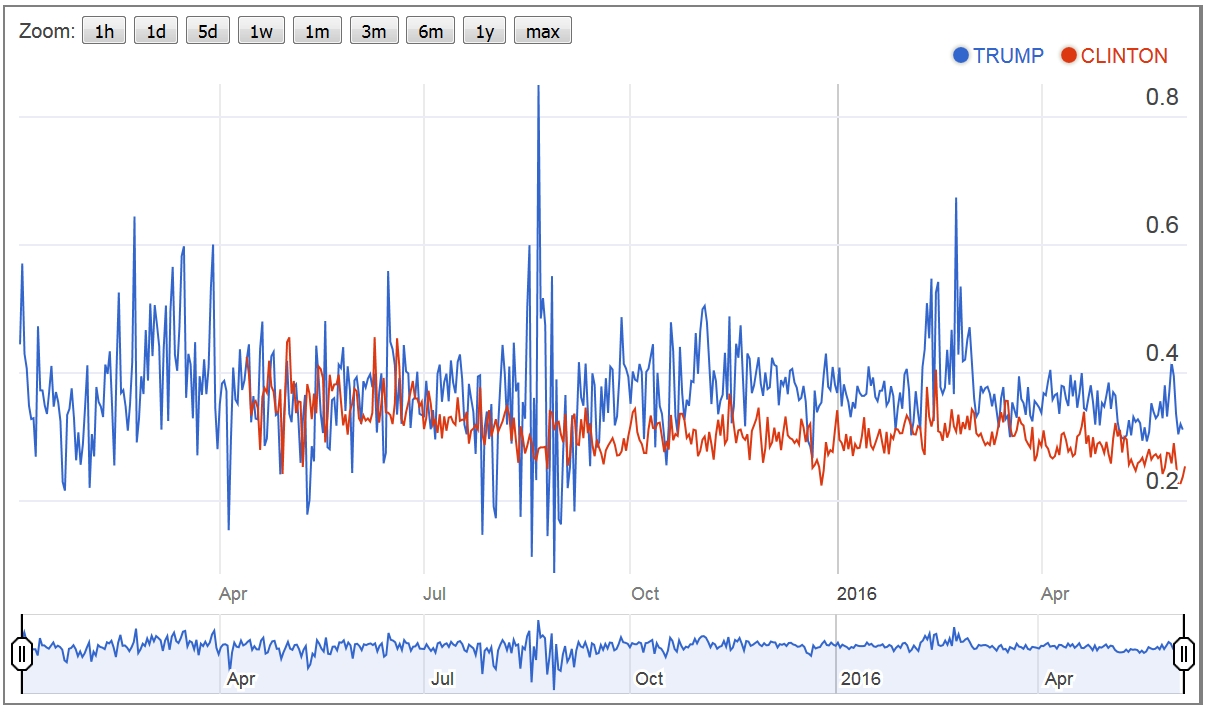
- Finally, the fourth figure shows the communities degree of self-centered style of expression, that is, if the communities write more in a more ‘inclusive’ (e.g., ‘we’) or ‘exclusive’ (e.g., ‘I’) style. The style of expression shows significant differences between Clinton and Trump. Trump’s fans express themselves in a more ‘exclusive’ style (36.12%), whereas Clinton’s fans express themselves in a more ‘inclusive’ style (30.28%).
Data: We crawled the nominees’ public page Facebook data, starting May 01, 2015 until May 31, 2016 via R ‘Rfacebook’. Specifically, we request all posts and corresponding comments for the entire time period (Clinton: approx. 1.2m comments / Trump: approx. 1.4m comments). Following this, each comment was analyzed separately with respect to emotional and psychological constructs (the categories are based on the LIWC dictionary) with R ‘tm’ and ‘quanteda’. The analysis does not include non-English content. Finally, we aggregate the data (comments) on a daily basis.
The data files are attached (for interactive graphics, open the txt files via Internet browser).
Figure1 Figure2 Figure3 Figure4
Here is a stylized example of the basic code (the code is limited to one candidate (Hillary Clinton), one day (2016-07-07), and refers to a public available dictionary (positive/negative word). The original analysis is based on the LIWC dictionary.
Analyzing the US elections with Facebook and R
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 |
library("Rfacebook") library("stringr") library("reshape2") ############################################################################# # Request Acces token (!!!!access token will only be valid for two hours!!!!)via: # https://developers.facebook.com/tools/explorer/ # Requires Facebook Account token <- "XXXX" ############################################################################# # Request posts # Simple Example: Hillary Clinton (posts for one day: 2017-07-07) fb_page<- getPage(page="889307941125736", token=token, since='2016/07/07', until='2016/07/08') fb_page$order <- 1:nrow(fb_page) # Function to download the comments download.maybe <- function(i, refetch=FALSE, path=".") { post <- getPost(post=fb_page$id[i], comments = TRUE, likes = TRUE, token=token) post1<- as.data.frame(melt(post)) } # Apply function to download comments files <-data.frame(melt(lapply(fb_page$order, download.maybe))) # Select only comments files_c<-files[complete.cases(files$message),] # Split ID to abstract POST_ID files_c$id2 <- lapply(strsplit(as.character(files_c$id), "_"), "[", 1) files_c$ch <- nchar(files_c$id2) files_a <- files_c[ which(files_c$ch >12), ] # Change column name names(files_a)[11]<-"POST_ID" # Define date files_a$date <- lapply(strsplit(as.character(files_a$created_time), "T"), "[", 1) files_a$date1<-as.character(files_a$date) # Dine identifier to count comments files_a$tempID<-1 ############################################################################# # Clean Data dat2<-gsub("[^[:alnum:]///' ]", "", files_a$message) dat2<-data.frame(dat2) dat3<-gsub("([.-])|[[:punct:]]", " ", dat2$dat2) dat3<-data.frame(dat3) dat4<-iconv(dat3$dat3, "latin1", "ASCII", sub="") dat4<-data.frame(dat4) dat5<-gsub('[[:digit:]]+', '',dat4$dat4) dat5<-data.frame(dat5) dat6<-tolower(dat5$dat5) dat6<-data.frame(dat6) dat7<-gsub("'", " ", dat6$dat6) dat7<-data.frame(dat7) dat8<-gsub("/", " ", dat7$dat7) dat8<-data.frame(dat8) ############################################################################# # Steps to replace empty entries # Function to replace blanks with missing NA blank2na <- function(x){ z <- gsub("\\s+", "", x) #make sure it's "" and not " " etc x[z==""] <- NA return(x) } # Replace blanks with 'NA' dat10<-data.frame(sapply(dat8, blank2na)) dat10<-data.frame(dat10) # Define the relevant column as numeric dat12<-as.numeric(dat10$dat8) dat12<-data.frame(dat12) # Define function if entry is numeric(non-numeric) f <- function(x) is.numeric(x) & !is.na(x) # Apply function dat14<-f(dat12$dat12) dat14<-data.frame(dat14) # Reverse definition of numeric/character dat16<-as.character(ifelse(dat14$dat14 == "FALSE", dat8$dat8, 1010101010101010)) dat16<-data.frame(dat16) dat16<-as.character(dat16$dat16) # Combine NA and real value !!!!Select a individual Term (here: "Hallo")!!!! dat8 <-as.character(dat8$dat8) dat17<-ifelse(dat16 != 1010101010101010, "HALLO", dat8) dat17<-data.frame(dat17) ############################################################################# # Define Corpus dat17$ch <- nchar(as.character(dat17$dat17)) dat17$bb <- ifelse(dat17$ch<4, "HALLO", as.character(dat17$dat17)) dat18 <- as.data.frame(dat17$bb [ grep("nchar", dat17$bb ) ]) dat17$dat17 <-as.character(dat17$dat17) dat_r <-as.data.frame(dat17) colnames(dat_r)[1] <-"dat_r" dat_r$dat_r <-as.character(dat_r$dat_r) corpus <- corpus(dat_r$dat_r) ############################################################################# # Load Dictionary (https://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html#lexicon) # Negative/Positive Words hu.liu.pos=scan('D:/positive-words.txt', what='character', comment.char = ';') hu.liu.neg=scan('D:/negative-words.txt', what='character', comment.char = ';') # Optional: Add Words to List pos.words=c(hu.liu.pos, 'like') neg.words=c(hu.liu.neg, 'bad') # Combine Dictionnarys myDict <- dictionary(list(positive = pos.words, negative = neg.words)) ############################################################################# # Apply Dictionary fb_liwc <-dfm(corpus, dictionary=myDict) fb1<-as.data.frame(fb_liwc) ############################################################################# # Combine Analysis Data and Original Data ALL<-cbind(files_a,fb1) |











