

What is H2O?
H2O is an awesome machine learning framework. It is really great for data scientists and business analysts “who need scalable and fast machine learning”. H2O is completely open source and what makes it important is that works right of the box. There seems to be no easier way to start with scalable machine learning. It hast support for R, Python, Scala, Java and also has a REST API and a own WebUI. So you can use it perfectly for research but also in production environments.
H2O is based on Apache Hadoop and Apache Spark which gives it enormous power with in-memory parallel processing.
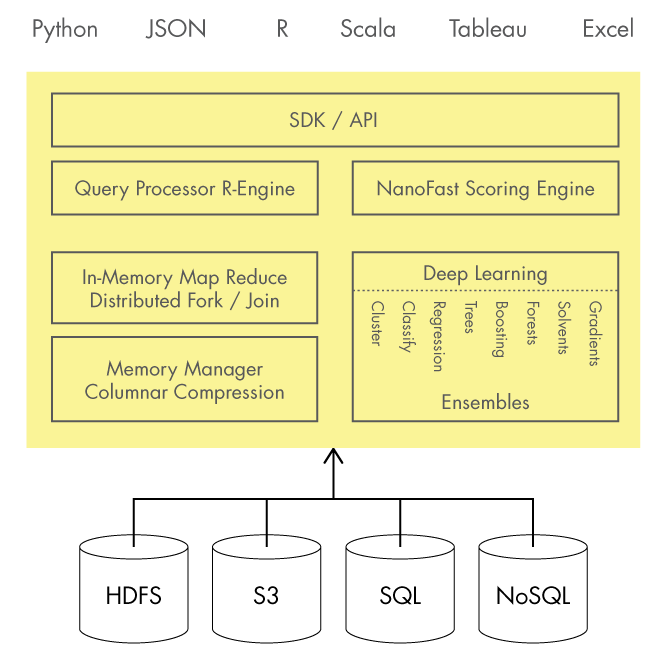
H2O is the #1 Java-based open-source Machine Learning project on GitHub and is used by really a lot of well-known companies like PayPal.
Get the data
The data we will use to train our machine learning model is from a Kaggle competition from the year 2013. The challenge was organized by Data Science London and the UK Windows Azure Users Group who partnered with Microsoft and Peerindex.
The data was described as: “The dataset, provided by Peerindex, comprises a standard, pair-wise preference learning task. Each datapoint describes two individuals, A and B. For each person, 11 pre-computed, non-negative numeric features based on twitter activity (such as volume of interactions, number of followers, etc) are provided.
The binary label represents a human judgement about which one of the two individuals is more influential. A label ‘1’ means A is more influential than B. 0 means B is more influential than A. The goal of the challenge is to train a machine learning model which, for pairs of individuals, predicts the human judgement on who is more influential with high accuracy. Labels for the dataset have been collected by PeerIndex using an application similar to the one described in this post.”
Theory to build the ensemble model
With the h2oEnsemble package we can create ensembles with all available machine learning models in H2O. As the package authors explain: “This type of ensemble learning is called “super learning”, “stacked regression” or “stacking.” The Super Learner algorithm learns the optimal combination of the base learner fits.”
This is based on the article “Super Learner” published in the magazine “Statistical Applications in Genetics and Molecular Biology” by Mark J. van der Laan, Eric C Polley and Alan E. Hubbard from the University of California, Berkeley in 2007. They also created the “SuperLearner” package based on that: SuperLearner
Install the dependencies
First of all we need the h2o package. This is available at CRAN and so are the packages SuperLearner and cvAUC we also need to build our model.
|
1 |
install.packages(c("h2o","SuperLearner","cvAUC")) |
The other and maybe most important package is the h2oEnsemble package. We can download it via devtools from the h2o GitHub repository.
|
1 2 3 |
require(devtools) install_github("h2oai/h2o-3/h2o-r/ensemble/h2oEnsemble-package") |
Then we just have to load all the packages:
|
1 |
require(c("h2o","h2oEnsemble", "SuperLearner", "cvAUC") |
Preparing the data
First we have to load the dataset with
|
1 |
dat<-read.csv("train.csv", header=TRUE) |
and split it into a train and a test data set. The test dataset provided by the Kaggle challenge does not include output labels so we can not use it to test our machine learning model.
We split it by creating a train index that chooses 4000 line numbers from the data frame. We then subset it into train and test:
|
1 2 3 |
train_idx <- sample(1:nrow(dat),4000,replace=FALSE) train <- dat[train_idx,] # select all these rows test <- dat[-train_idx,] # select all but these rows |
Preparing the ensemble model
We begin with starting an h2o instance directly out of our R console
|
1 |
localH2O = h2o.init() |
After starting the H2O instance, we have to transform our data set a little bit further. We have to transform it into H2O data objects, define the output column and set the family variable to binomial as we want to do a binomial classification.
That is also the reason why we have to turn the output columns into factor variables.
|
1 2 3 4 5 6 7 |
training_frame <- as.h2o(localH2O, train) validation_frame <- as.h2o(localH2O, test) y <- "Choice" x <- setdiff(names(training_frame), y) family <- "binomial" training_frame[,c(y)] <- as.factor(training_frame[,c(y)]) #Force Binary classification validation_frame[,c(y)] <- as.factor(validation_frame[,c(y)]) # check to validate that this guarantees the same 0/1 mapping? |
Then we can define the machine learning methods we want to include in our ensemble and set the meta learner from the SuperLearner package. in this case we will use a general linear model.
|
1 2 3 4 |
# Specify the base learner library & the metalearner learner <- c("h2o.glm.wrapper", "h2o.randomForest.wrapper", "h2o.gbm.wrapper", "h2o.deeplearning.wrapper") metalearner <- "SL.glm" |
Build the model to predict Social Network Influence
After defining all the parameters we can build our model.
|
1 2 3 4 5 6 |
fit <- h2o.ensemble(x = x, y = y, training_frame = training_frame, family = family, learner = learner, metalearner = metalearner, cvControl = list(V = 5, shuffle = TRUE)) |


Evaluate the performance
Evaluating the performance of a H2O model is pretty easy. But as the ensemble method is not fully implemented in the H2O package yet, we have to create a small workaround to get the accuracy of our model.
|
1 2 3 4 |
pred <- predict.h2o.ensemble(fit, validation_frame) labels <- as.data.frame(validation_frame[,c(y)])[,1] # Ensemble test AUC AUC(predictions=as.data.frame(pred$pred)[,1], labels=labels) |
In my case the Accuracy was nearly 88%, which is a pretty good result.
You can also look at the accuracy of the the single models you used in your ensemble:
|
1 2 |
L <- length(learner) sapply(seq(L), function(l) AUC(predictions = as.data.frame(pred$basepred)[,l], labels = labels)) |












{kind=link}