
You can use this tutorial in the ThinkToStartR package and create your Twitter sentiment word cloud in R with:
Hey everybody,
some days ago I created a wordcloud filled with tweets of a recent german news topic. And a lot of people asked me if I have some code how I created this cloud. And so here it is.
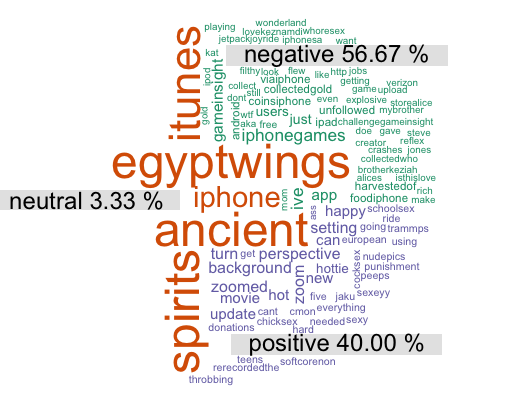
In the end the plot will basically look like this:

It uses tweets and the datumbox twitter-sentiment API.
Preparation:
First let´s get a datumbox API key like I described in this tutorial:
In the first step you need an API key. So go to the Datumbox website http://www.datumbox.com/ and register yourself. After you have logged in you can see your free API key here: http://www.datumbox.com/apikeys/view/
Like always when we want to work with Twitter we have to go through the authentication process like I described here.
And then we need some packages for this tutorial but they are all available at CRAN:
|
1 2 3 4 5 6 |
library(twitteR) library(RCurl) library(RJSONIO) library(stringr) library(tm) library(wordcloud) |
The last preparation step is defining two functions which will help us a lot. The first cleans the text we send it and removes unwanted chars and the second sends the text to the datumbox API.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
clean.text <- function(some_txt) { some_txt = gsub("(RT|via)((?:\b\W*@\w+)+)", "", some_txt) some_txt = gsub("@\w+", "", some_txt) some_txt = gsub("[[:punct:]]", "", some_txt) some_txt = gsub("[[:digit:]]", "", some_txt) some_txt = gsub("http\w+", "", some_txt) some_txt = gsub("[ t]{2,}", "", some_txt) some_txt = gsub("^\s+|\s+$", "", some_txt) some_txt = gsub("amp", "", some_txt) # define "tolower error handling" function try.tolower = function(x) { y = NA try_error = tryCatch(tolower(x), error=function(e) e) if (!inherits(try_error, "error")) y = tolower(x) return(y) } some_txt = sapply(some_txt, try.tolower) some_txt = some_txt[some_txt != ""] names(some_txt) = NULL return(some_txt) } getSentiment <- function (text, key){ text <- URLencode(text); #save all the spaces, then get rid of the weird characters that break the API, then convert back the URL-encoded spaces. text <- str_replace_all(text, "%20", " "); text <- str_replace_all(text, "%\d\d", ""); text <- str_replace_all(text, " ", "%20"); if (str_length(text) > 360){ text <- substr(text, 0, 359); } ########################################## data <- getURL(paste("http://api.datumbox.com/1.0/TwitterSentimentAnalysis.json?api_key=", key, "&text=",text, sep="")) js <- fromJSON(data, asText=TRUE); # get mood probability sentiment = js$output$result ################################### return(list(sentiment=sentiment)) } |
Let´s start!
First we have to get some tweets:
|
1 |
tweets = searchTwitter("iPhone", 20, lang="en") |
Then we get the text from these tweets and remove all the unwanted chars:
|
1 2 3 4 5 6 |
# get text tweet_txt = sapply(tweets, function(x) x$getText()) # clean text tweet_clean = clean.text(tweet_txt) tweet_num = length(tweet_clean) |
Now we create a dataframe where we can save all our data in like the tweet text and the results of the sentiment analysis.
|
1 |
tweet_df = data.frame(text=tweet_clean, sentiment=rep("", tweet_num),stringsAsFactors=FALSE) |
In the next step we apply the sentiment analysis function getSentiment() to every tweet text and save the result in our dataframe. Then we delete all the rows which don´t have a sentiment score. This sometimes happens when unwanted characters survive our cleaning procedure.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# apply function getSentiment sentiment = rep(0, tweet_num) for (i in 1:tweet_num) { tmp = getSentiment(tweet_clean[i], db_key) tweet_df$sentiment[i] = tmp$sentiment print(paste(i," of ", tweet_num)) } # delete rows with no sentiment tweet_df <- tweet_df[tweet_df$sentiment!="",] |
Now that we have our data we can start building the wordcloud.
The Wordcloud
First we get the different forms of sentiment scores the API returned. If you used the Datumbox API you will have positive, neutral and negative. With the help of them we divide the tweet texts into categories.
|
1 2 |
#separate text by sentiment sents = levels(factor(tweet_df$sentiment)) |
The next line of code seems to be a little bit complicated. But it is enough if you know that it generates labels for each sentiment category which include the percents.
|
1 2 3 |
# get the labels and percents labels <- lapply(sents, function(x) paste(x,format(round((length((tweet_df[tweet_df$sentiment ==x,])$text)/length(tweet_df$sentiment)*100),2),nsmall=2),"%")) |
Then we create the so called docs for each category and add the tweet texts to these categories:
|
1 2 3 4 5 6 7 8 |
nemo = length(sents) emo.docs = rep("", nemo) for (i in 1:nemo) { tmp = tweet_df[tweet_df$sentiment == sents[i],]$text emo.docs[i] = paste(tmp,collapse=" ") } |
The next steps are the same steps you would use for a “normal” worcloud. We just create a TermDocument Matrix and call the function comparison.cloud() from the “wordcloud” package
|
1 2 3 4 5 6 7 8 9 10 11 |
# remove stopwords emo.docs = removeWords(emo.docs, stopwords("german")) emo.docs = removeWords(emo.docs, stopwords("english")) corpus = Corpus(VectorSource(emo.docs)) tdm = TermDocumentMatrix(corpus) tdm = as.matrix(tdm) colnames(tdm) = labels # comparison word cloud comparison.cloud(tdm, colors = brewer.pal(nemo, "Dark2"), scale = c(3,.5), random.order = FALSE, title.size = 1.5) |
Of course you can find the whole code on github.
And if you always want stay up to date about my work and the topics R, analytics and Machine Learning feel free to follow me on Twitter











