

The field of data mining is exploding with new participants using an array of tools that are applying novel analytical approaches to exponentially increasing amounts of data. Due to the discipline’s dynamic growth and seemingly limitless number of applications, it is beneficial to keep in mind that data mining is guided by a process referred to as CRISP-DM (cross-industry standard process for data mining) that is applicable no matter what type of problem we are trying to solve, regardless of where the data is coming from, and irrespective of tools and methods used to analyze the data.
The Data Mining Process:
Step 1 in the CRISP-DM process is understanding the business problem(s) that we are trying to solve. To forge an understanding of the business problem, we need to have an overarching understanding of the business, itself. I work in higher education marketing and will use that industry and some data to illustrate an example of a predictive modeling assignment where I am attempting to develop a model to predict which high school students in the college’s database will eventually enroll at the school. This example also incorporates Step 2 of the the CRISP-DM process: understanding the data.
The image below depicts a spreadsheet containing historical enrollment data at a college where the outcome that we are trying to predict (column G) moving forward is binary – will the student enroll: Yes or No?
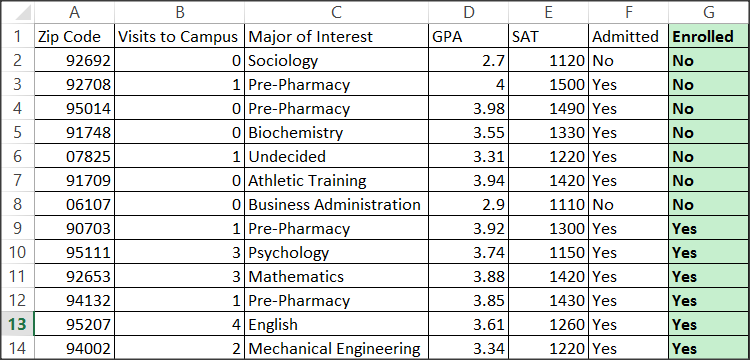
Working in this industry, I know that there tend to be several variables that are predictive in the enrollment equation: geographic location, what major the student is interested in, academic record, test scores, etc. However, I also need to have a nuanced understanding of how this business works and what the relationships among these variables are – not only in terms of correlation, but in terms of timing. Notice Column F (Admitted). There are two rows (2 and 8) indicating “No.” At first glance, I might be tempted to include this column in my model. Yet, being admitted to the college is a necessary condition of enrolling. In other words, a student cannot attend if he/she has been denied admission. Therefore, I need to apply my business knowledge to identify the fact that Column F should not be included in my model. Instead, I will end up using that column as a filter to ensure that I only develop the model using records that have a “Yes” in Column F. Not only am I not interested in students who weren’t granted admission, but I know that a “No” in column F automatically leads to a “No” in Column G (the outcome of interest). On the flipside, we can see that there are records in this spreadsheet with a “Yes” in Column F and both possible outcomes in Column G. That is what we are interested in: developing a model to help us predict why someone who has been admitted to the college ultimately ends up enrolling or not.
Without an understanding of the higher education industry, it would have been very easy for me to have taken that spreadsheet, included all of the variables, and developed a model. As the example above illustrated, that would have been a mistake. No software tool that I could have selected nor data mining algorithm could have corrected that mistake for me.
Do you have any examples of how a lack of business understanding could lead you to use inappropriate data when developing a model?










